本文着重于源码实现,基于 mariadb 11.8 版本。
概述
MariaDB vector index 实现分析 用通俗易懂的语言描述了 mariadb 的 vector index 实现原理,以及性能分析。核心如下图:
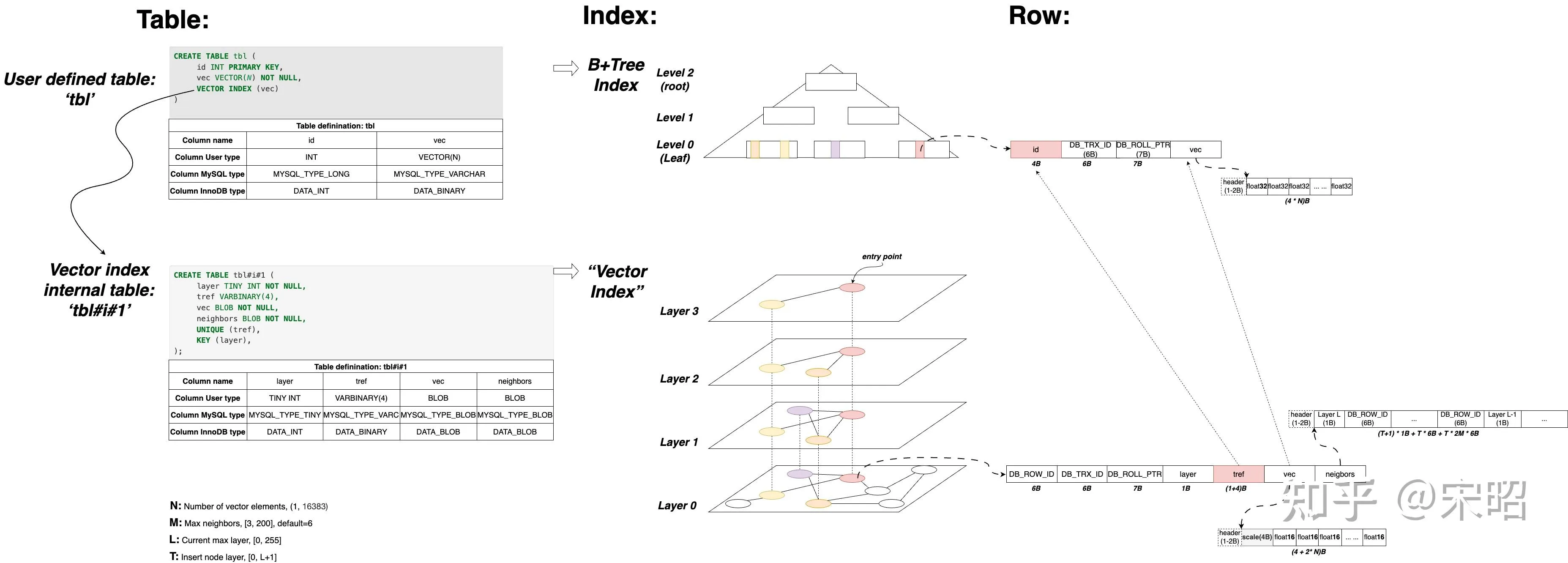
通过这幅图,可以清楚的看出来:
- 向量索引保存在一张内部表中,姑且称为“向量索引表”
- 向量保存了两份,一份在用户表中,一份保存在向量索引表中
- 向量采用二进制的形式保存
- 向量索引表中保存的向量经过了量化,每一个向量维度使用 int16 保存,也就是 2字节
- 向量所有层的邻居都保存在 neighbors 字段中
- neighbors 字段保存的是邻居 id,即
DB_ROW_ID
向量索引表的建表语句定义在 mhnsw_hlindex_table_def 函数中,如下所示:
CREATE TABLE `用户表表名 + #i# + vector列位置` (
layer tinyint not null, -- (最高)层数
tref varbinary(%u), -- 用户表的主键值,用于内部表记录与对应用户表记录的关联
vec blob not null, -- 向量数据,与主表存储方式不同
neighbors blob not null, -- 该节点在每一层的邻居,存的是 DB_ROW_ID
unique (tref),
key (layer)
)mariadb 的向量索引基于 hnsw 算法,并做了修改。关于 hnsw 可以参考 HNSW 论文。 从上面这幅图中,已经大致可以窥探出 mariadb 实现 hnsw 的思路:用表来模拟内存的数据结构。那么,它是如何处理 hnsw 的局限性的呢?
HNSW 的局限性
hnsw 是比较高效的向量索引数据结构,也是目前应用最广泛的 ann 算法。
但它有几个问题:
- 纯内存的数据结构,必须全部加载到内存中才能使用
- 随机读,访问某个节点的邻居是随机读,是实现磁盘算法的一大挑战
- 写放大,当插入向量时,不仅要修改该节点,还要更新其邻居节点的连接信息。这些节点可能分散在磁盘各处,导致大量的小规模随机写入,远比顺序写入效率低
- 事务能力缺失
mariadb 实现
数据类型
用户使用 VECTOR 关键字指定向量数据类型,如下所示:
CREATE TABLE products (
name varchar(128),
description varchar(2000),
embedding VECTOR(4) NOT NULL,
VECTOR INDEX (embedding) M=6 DISTANCE=euclidean
);- M:是 hnsw 算法的参数,表示每个节点拥有多少个邻居
- DISTANCE:指定距离度量方式,目前支持两种:euclidean 为欧氏距离,cosine 为余弦距离
对外显示 vector 数据类型,但在内部,mariadb 使用 varchar 存储数据。
mariadb 使用 udt 机制来扩展支持 vector 类型。
当往 vector 列插入数据时,需要通过 VEC_FromText 函数将向量数据转换为 varchar 数据:其工作原理是将向量数据当作 json 的数组进行解析,对于 json array 的每一项,使用 strntod 将字符串转为 float,再通过 float4store 转为4字节二进制,最终将这些二进制 append 到一起。所以,vector(n) 占用的空间为 n * 4 字节。
vector 匹配的语法规则如下所示:
udt_name float_options srid_option
{
if (Lex->set_field_type_udt(&$$, $1, $2))
MYSQL_YYABORT;
}set_field_type_udt 中能够识别并返回 type_handler_vector 实例,这是一个全局变量,类型为 Type_handler_vector,处理 vector 类型。
在建表流程中,会调用到 Type_handler 的 make_table_field_from_def 接口完成转换,将 Type_handler 转换为 Filed。vector 类型对应的类型为 Field_vector。Field 中保存了 server 层和存储层数据交互的桥梁: ptr 指针,通过 Field 的 store 方法,可以将数据保存在 ptr 所指向的内存中,并交给存储引擎。
Field_vector 是 Field_varstring 的子类,其 store 方法会最终调用 Field_varstring 的 store 方法。Field_vector 只实现了接收 const char * 的 store 方法,意味着:在往 vector 类型插入数据前,必须要调用 VEC_FromText 函数将向量数据转换为二进制表示方式,或者直接插入二进制数据。
VEC_FromText 对应的类为:Item_func_vec_fromtext,其 val_str 完成将向量类型字面值转换为二进制,之后调用 Field_vector 的 store 函数存入 ptr 中。
思考题: duckdb array 类型实现:duckdb 的 array 实现逻辑和 c++ 中的二维数组的思路是一致的,即:数据实际上是保存在一维数组中(连续空间),在逻辑上做切分,对用户表现为二维。 在 mysql 中能否也参考这种思想,即: 将 vector 类型扩展成多个 float 列,可不可行?
索引创建流程
mariadb 引入了 “high level index”(hlindex)机制,来支持创建向量索引。所谓的 hlindex 是指:sql 层索引,非引擎层索引。目前,mariadb 中只支持一种 hlindex:向量索引。
通过在普通建表流程中增加对 hlindex 的支持,完成向量索引的创建:在 ha_create_table 的最后,如果检测到表上含有 hlindex,就会创建向量索引表。
hlindex 的判断逻辑:
uint hlindexes() { return total_keys - keys; }- total_keys:表示创建表时指定的所有索引的数目,包含 hlindex,目前 hlindex 就是指向量索引
- keys:存储引擎上创建的索引数目
创建向量索引表的步骤如下:
ha_create_table {
// ... 正常的建表流程
if (share.hlindexes()) { // 表上创建了 high level 索引
1. init_tmp_table_share // 初始化临时 index_share
2. mhnsw_hlindex_table_def // 取回建表语句
// 用建表语句初始化 index_share
3. index_share.init_from_sql_statement_string
4. ha_create_table_from_share // 创建临时表
}
}索引参数
mariadb 向量索引实现相关参数:
| 参数 | 默认值 | 范围 | 说明 |
|---|---|---|---|
| mhnsw_max_cache_size | 16MB | [1MB, SIZE_T_MAX] | 单个索引缓存上限 |
| mhnsw_ef_search | 20 | [1, 10000] | 查询时探索的候选节点数 |
| mhnsw_default_m | 6 | [3, 200] | 创建索引时的默认 M 值 |
| mhnsw_default_distance | EUCLIDEAN | EUCLIDEAN/COSINE | 默认距离度量 |
插入
往包含向量索引的表中插入数据时,会自动构建 hnsw 索引。
INSERT INTO products (name, description, embedding)
VALUES ('Coffee Machine',
'Built to make the best coffee you can imagine',
VEC_FromText('[0.3, 0.5, 0.2, 0.1]'))mariadb 插入流程入口 mysql_insert,通过修改正常的插入逻辑,完成在数据插入到主表的同时,也会插入到向量索引表中,大致流程如下:
mysql_insert
├─→ open_and_lock_tables
├─→ prepare_for_replace
│ └─→ prepare_for_modify
│ └─→ open_hlindexes_for_write
│ ├─→ hlindex_open
│ └─→ hlindex_lock
├─→ fill_record_n_invoke_before_triggers
└─→ write_record
└─→ single_insert
└─→ ha_write_row
├─→ write_row
└─→ hlindexes_on_insert -> mhnsw_insert-
调用
open_hlindexes_for_write,对向量索引表进行开表:先调用hlindex_open开表,然后调用hlindex_lock锁表 -
在
ha_write_row中,完成了对主表的写入(write_row)之后,写 binlog 之前(binlog_log_row),调用hlindexes_on_insert往向量索引表插入数据
构建 hnsw 的入口:mhnsw_insert,本质上还是构建 hnsw 结构,使用的算法和论文中是一致的,此文中不再赘述。
FVectorNode
作者的设计思想是:将向量索引表视为 graph,将表中的一条数据视为 graph 的一个 node。在代码实现中,FVectorNode 就承担了这个角色:既表示一个节点,同时也表示表中的一条数据。
FVectorNode 如下所示:

- ctx:指向
MHNSW_Share(下文中介绍),指针类型,8字节 - vec:保存的是二进制形式的向量,指针,8字节
- neighbors:邻居指针,每一层对应一个
Neighborhood,8字节 - max_layer:节点最高层,1字节
- stored:是否存入了表中,1bit
- deleted:删除标记,1bit
FVectorNode 采用了单字节对齐的内存格式,内存布局如下:

gref 和 tref 的内存是不属于 FVector 的,它们紧跟在 FVector 的后面:
- gref 保存向量索引表的主键 DB_ROW_ID,可以理解为是节点的唯一编号
- tref 保存的是主表的主键,用于回表
P.S. 感觉这么设计的必须是大佬,对内存的管理非常熟练,否则很容易出问题
neighbors 指向一块连续的内存:前面是 max_layer + 1 个 Neighborhood(一层一个),后面跟着的是若干个 FVector* 指针。
每一个 Neighborhood 所包含的 FVector* 只与 M 有关系,mariadb 的实现跟论文稍微有点区别:
// 把数值 A 向上对齐到 L 的倍数(L 必须是 2 的幂)
#define MY_ALIGN(A,L) (((A) + (L) - 1) & ~((L) - 1))
void *alloc_neighborhood(size_t max_layer)
{
mysql_mutex_lock(&cache_lock);
auto p= alloc_root(&root, sizeof(Neighborhood)*(max_layer+1) +
sizeof(FVectorNode*)*(MY_ALIGN(M, 4)*2 + MY_ALIGN(M,8)*max_layer));
mysql_mutex_unlock(&cache_lock);
return p;
}论文中,每个节点在第 0 层拥有 2*M 个邻居,其他层拥有 M 个邻居,mariadb 多了一个对齐的逻辑,如上所示。
FVectorNode 的 make_vec 方法负责将用户的向量数据进行量化,转换为2字节的形式,提高并行计算的速度。在代码中,
向量数据对应的数据结构是 FVector,其提供了 AVX2,AVX512,ARM NEON,POWERPC 等多种体系架构或者指令集下的
点积的计算方式。
make_vec 实际调用的是 FVector 的 create 方法,算法思想如下:
max_float <- 找到维度最大值
scale <- max_float / INT16_MAX // scale:量化因子,将 float 映射到 int16
dim[i] <- dim[i] / scale
abs2 <- 原始向量的平方模的一半
if metric == COSINE:
scale <- scale / std::sqrt(2*abs2)
abs2 <- 0.5f;
endif当向量距离度量方式为余弦时,通过调整 scale,巧妙地实现了原始向量归一化。
下面回答一些问题:
Q:如何处理随机写入的问题
构建 hnsw 不仅需要更新当前节点的邻居,对于当前节点的所有邻居,仍然需要更新它们的邻居,这块内容对应 update_second_degree_neighbors。
从代码看,mariadb 现在的实现似乎并没有处理写放大的问题。
Q:插入重复向量是怎么处理的
从 insert 的流程来看,重复向量在内部会被视为独立的数据点。从内部表的定义也可以看出来:
内部表采用了没有主键,内部使用 DB_ROW_ID 作为主键,也就是说相同的向量具有不同的 DB_ROW_ID。
删除
一种是 truncate,直接调用 mhsnw_delete_all 清空向量索引表;另一种是 delete row,采用标记删除。
流程如下:
ha_delete_row -> mhnsw_invalidate
ha_truncate -> hlindexes_on_delete_all -> mhnsw_delete_all需要删除所有数据时, truncate 效率比 delete 高很多。
更新
采用标记删除,并且插入新的数据点,流程如下:
ha_update_row -> hlindexes_on_update --> mhnsw_invalidate
`-> mhnsw_insertmhnsw_invalidate 主要做了两件事
- 根据待删除的向量,找到向量索引表的行,然后将向量索引表的 tref 字段置为 null
- 将 FVectorNode 的 delete 字段置为 true
通过将 tref 字段置为 null,可以保证在搜索结果中不会出现被删除的节点;另外一方面,虽然用户删除某个节点,我们依然可以使用被删除的节点作为路由,进行搜索。
Q:那么什么时候真正地删除?
TODO(P.S. 目前的理解是不删除)
查询
查询示例:
SELECT p.name, p.description
FROM products AS p
ORDER BY VEC_DISTANCE_EUCLIDEAN(p.embedding,
VEC_FromText('[0.3, 0.5, 0.1, 0.3]'))
LIMIT 10优化器
优化器在什么情况下会选择向量索引呢?
简要回答:order by 需搭配 limit 子句,且 order by 子句中使用 vec_distance 函数,且走向量索引的代价最低。
在 find_indexes_matching_order 函数中会调用 order by 表达式的 part_of_sortkey 函数,这个函数会返回 order by 能够使用哪些索引,而 VEC_DISTANCE_* 函数只会返回向量索引(对应 Item_func_vec_distance::part_of_sortkey 实现)。part_of_sortkey 返回的索引会被作为 usable_keys 继续参与后续评估。
后续在 test_if_cheaper_ordering 函数中还会对索引进行诸多检查:
test_if_order_by_key,检查索引是否满足 order by 的排序要求- 索引需满足以下条件之一
- 覆盖索引(
is_covering) - 有 limit 子句(
has_limit) - 优化器强制要求使用索引合并策略(
force_index_merge) - 特定场景(
ref_key < 0 && (group || table->force_index))
- 覆盖索引(
- 计算代价(
get_range_limit_read_cost),选出 cost 最低的执行路径(P.S. 也会与 file sort 比较代价)
mariadb 似乎并没有对向量索引的代价计算做特殊的处理。
总结一下:选择向量索引的必要条件是对向量列按距离 topk 排序,但实际上不一定会使用向量索引,需要结合 optimizer_trace 进行分析。 对于上面示例中的 select 语句,如果去掉了 limit 子句,就不会选用向量索引。
查询流程
sub_select --> join_read_first -> hlindex_read_first -> mhnsw_read_first
`-> read_record -> join_hlindex_read_next -> mhnsw_read_next查询分为两个接口:
- mhnsw_read_first
- mhnsw_read_next
在 mhnsw_read_first 中运行 hnsw search 算法,将结果以 Search_context 的形式保存在 table->hlindex->context 中,后续 next 根据 Search_context 回表取数据。
缓存机制
为了避免每次随机读,mariadb 设计了 node_cache 来缓存 FVectorNode,node_cache 保存在 MHNSW_Share 中。
node_cache 是一个 hash 表,key 是向量的 id,value 是 FVectorNode 。每次需要读取向量索引表时(get_node),
都会先从 node_cache 中找一下,找不到会新建一个 FVectorNode 放到 node_cache 中。
mariadb 并没有很好的解决随机读的问题。使用了缓存机制, 包括 mhnsw 的 node_cache 和 innodb 的 buffer pool 机制来缓存数据,避免后续的磁盘 io。但是,其实并没有从根本上解决问题,当缓存满了以后,性能出现波动。
事务分析
数据结构
MHNSW_Trx 是 non-shared 事务上下文,以单链表的形式存储在 thd->ha_data 中,
每个 MHNSW_Trx 对应一张表:在事务中第一次往表中插入数据时创建,
按照写表的顺序串成单链表(反向的,越后来的表越在前),
thd->ha_data 保存的最近写的表的 MHNSW_Trx。
MHNSW_Share 是共享的算法上下文,保存 hnsw 的 entrypoint,
缓存访问过的 hnsw 的节点。 MHNSW_Share 保存在 TABLE_SHARE
的 hlindex 成员变量中,是跨 session 共享的,如下所示:
struct TABLE_SHARE
{
union {
void *hlindex_data; /* for hlindex tables */
TABLE_SHARE *hlindex; /* for normal tables */
};
}在 TABLE_SHARE 中添加了一个联合体:
- 对于普通表,保存的是向量索引表
- 对于向量索引表,保存的则是
MHNSW_Share
MHNSW_Trx 是 MHNSW_Share 的子类,MHNSW_Trx 在 share 的基础上增加了事务的能力,实现了一系列相关接口,包含:
- 提交:
do_commit - 回滚:
do_savepoint_rollback,do_rollback
当事务第一次写入(包括更新,删除)时,会申请 MHNSW_Trx,只读事务由于未申请 MHNSW_Trx,也没有提交的逻辑。
获取 MHNSW_Share 的流程如下:

从流程图中也可以看出,thd 中保存的 MHNSW_Trx 的优先级是高于 TABLE_SHARE 中保存的 MHNSW_Share 的。
entrypoint 是 hnsw 的入口点,在 faiss 的实现逻辑中,是以成员变量的形式保存在内存中,当插入更高 layer 的节点后,更新 entrypoint。
在 mariadb 的实现中,每个 MHNSW_Share 都会保存自己 hnsw 入口点,对应代码中的 start 变量。
一开始都会从向量索引表中读取 max_layer 节点作为 entrypoint,后续也是在插入流程中维护,逻辑和 faiss 相似。
加载 entrypoint 的逻辑如下:
ha_index_init(IDX_LAYER, 1); // 使用 layer 索引
graph->file->ha_index_last; // 获取最后一个节点,即最大层
node->load_from_record; // 读向量索引表,加载 entrypoint
(*ctx)->start= node; // 保存到 start 中首先使用 layer 索引,定位的 max_layer 的某一个节点,然后回表,加载该节点。这个节点就会被当作 entrypoint。
生命周期
MHNSW_Share 中定义了 refcnt 成员变量,即引用计数,维护对象生命周期。
第一次申请 MHNSW_Share 时,会将 MHNSW_Share 绑定到 table share 上,并将 refcnt 会置为 1,只有在解绑时才会减掉此处的 +1 操作。
另外,申请时仍然算做一次访问,还需要 ++refcnt。后续访问,正常 ++refcnt
每次读取数据时,都会进行检查,当内存超过设定的值时(mhnsw_max_cache_size),会对 MHNSW_Share 解绑,当 MHNSW_Share 当引用计数为 0 时,
会释放空间,包括前文提到的 node_cache。
MHNSW_Trx 也继承了 refcnt,在事务中,每次读写操作,都会检查对内存进行检查,当超限后会及时释放空间。不同的是,当事务结束以后,MHNSW_Trx
的生命周期也结束了,会主动析构,释放空间。
提交、回滚
流程如下:

- 对于写操作,写完之后都会调用
trans_commit_stmt作语句级别的提交 - 对于 commit 语句,调用
trans_commit提交事务 - 对于 rollback 语句,调用
trans_rollback回滚事务 - 对于 rollback to savepoint 语句,调用
trans_rollback_to_savepoint回滚到指定 savepoint
MHNSW_Trx::do_commit
- 会加提交锁(
commit_lock),防止读写冲突 - 操作事务涉及到的所有表,将它们 table share 中的 MHNSW_Share 的 start 置为空,强制后续操作重新读取 hnsw 的 entrypoint;将 node_cache 中所有的 FVectorNode 的 vec 置为空,强制从向量索引表中重新读取最新数据
MHNSW_Trx::do_rollback
析构事务涉及到的所有表的 MHNSW_Trx,同时清空 thd 中的 MHNSW_Trx 信息。
ha_rollback_trans 还会调用 innodb 的回滚逻辑 innobase_rollback 完成主表和向量索引表的数据回滚。
隔离性
如何支持处理写写冲突,读写冲突的?
- 由于所有操作都需要获取 entrypoint,而写操作会对 entrypoint 加 x 锁,导致写写无并发;
- read 使用快照读,不需要加锁。
崩溃恢复
挂了以后的恢复流程,会不会丢数据?
因为采用了 innodb 存储图结构,基于 innodb 的崩溃恢复流程,可以保证数据的安全。